회사를 그만두고 비교적 자유로운 시간이 생기면서, 평소 어설프게만 알고 있었던 딥러닝을 조금은 체계적으로 공부해보기로 했다. 아무래도 CS를 전공하다 보니, 이곳저곳에서 딥러닝에 대한 이야기를 조금씩은 얻어들을 수 있었다. 하지만 지식이 얕아 그런 대화에 적극적으로 참여하지 못했던 게 줄곧 아쉬움으로 남아서였을까? 어쨌든 남는 시간이 생기면서 1순위로 생각했던 게 ‘딥러닝’이었다.
마침 Udemy에서 무료로 제공하는 김대방님의 Keras를 활용한 Deep Learning 입문 강좌를 접하게 되었고, 꾸준히 들어 완강할 수 있었다. 물론 입문 강좌이니만큼, 강의를 들은 후에 딥러닝에 대해 알게 됐다는 뿌듯함보다는 더 배워야 할 것들이 엄청 많이 있다는 걸 깨닫고 슬퍼진 게 더 크다. 그렇지만 일단은 이 정도로 첫 걸음을 떼어놓기로 했다. 딥러닝에 대한 소소한 교양(?)을 쌓는다는 기분으로 알게 된 용어들을 차곡차곡 정리해보기로 했다.
Machine Learning? Deep Learning?
머신 러닝이란 무엇인가? 딥러닝은 무엇일까? 하는 주제로 검색하면 직관적인 예시에서부터 자세하고 기술적인 정의까지 많은 좋은 글들을 볼 수 있다. 둘의 관계는 명확하다. 딥러닝은 머신 러닝 분야에서 주목받는 하나의 기법이다. 먼저 더 general한 개념인 머신 러닝에 대해, 나름의 이해를 기반으로 짚고 넘어가려고 한다. 머신 러닝은 기본적으로 코드를 쓰기 싫은 사람들을 위한 아이디어다. 프로그래머가 머리를 짜내어 프로그램, 작게는 어떤 함수를 작성하는 과정을 상상해 보자. 이왕이면 TDD로! 그렇다면 함수의 Unit Test를 작성할 때 우리가 가장 먼저 하는 일이 뭘까? 바로 Test Case를 모으는 것이다. 머신 러닝을 이용하면, 사실 여기서 끝이다. Test Case만 주어지면 모델이 알아서 적합한 로직을 만들어낸다. Test Case가 좀 많이.. 아주 많이…. 필요하기는 하지만.
그렇기 때문에 어떻게 보면 머신러닝 모델을 굉장히 유연한 함수 - 또는 과장을 보태어 ‘만능 함수’로 여길 수도 있다. 어떤 종류의 input과 output이든 그 데이터에 맞게 자신을 변형시켜서 모든 문제를 풀 수 있는 일반 알고리즘(generic algorithm)을 생성해낸다는 아이디어이니 말이다. 아직까지 결국 적합한 모델을 인간이 골라야 하기는 하지만.
기계 학습의 분류
- 지도 학습 (supervised learning): 데이터에 대한 label(명시적인 정답)이 주어진 상태에서 학습
- 비지도 학습 (unsupervised learning): 데이터에 대한 label이 주어지지 않는 상태에서 학습한다. 데이터를 비슷한 특성으로 묶는 Clustering 알고리즘, Hidden Feature를 발견하는 데에 사용한다.
- 강화 학습 (reinforcement learning): 앞에서는 데이터가 주어진 정적인 상태(static environment)에서 학습을 진행했지만, 강화학습은 agent가 주어진 환경(state)에 어떤 행동을 취하고 이로부터 보상을 얻으면서 학습을 진행하고, 보상을 최대화하는 방향으로 학습이 진행된다.
(오류가 있다면 댓글로 알려주셔서 저를 강화학습시켜주세요!)
Part 1: DNN
DNN은 Deep Neural Network의 약자로, 딥러닝을 위해 사용한다. 여러 개의 뉴런(을 본딴 함수)으로 이루어졌다.
Perceptron: 하나의 인공 신경 구조
Neural Network에서 하나의 뉴런에 대응되는 구조이다. 머신 러닝의 초기 단계에서는 단일 Perceptron으로 모델을 구축하고자 했지만 한계에 다다르게 되었고, 이후 Perceptron으로 이루어진 Layer 계층 구조를 발전시켜 Deep Neural Network를 구성하게 됐다.
Deep Neural Net
Perceptron과는 달리 여러 개의 노드가 함께 연결되어 있다. 기본적으로 Feed Forward -> Back Propagation으로 이뤄지는 학습 과정은 Perceptron과 같다.
-
Input Layer -> Hidden Layer -> Output Layer 로 구성되어 있다.
- Hidden layer
- 2개의 function(Linear Function, Activation Function)으로 구성된다. 여기서 Activation Function은 non-linearity를 반영해야 한다. 현실의 데이터는 n차원의 비선형 분포로 존재한다. 그러므로 이것이 Activation Function의 존재 이유가 된다. Neural Network에서 비선형 분포를 반영할 수 있도록 해야 하기 때문이다.
-
Feed Forward: 주어진 input x에서 뉴럴넷을 거쳐 y를 계산하는 (정방향의) 과정. cycle을 형성하지 않는다.
-
Error Function (=Cost Function, Loss Function): Neural Net 모델이 Feed Forward로 계산한 값과 실제 타겟 값을 비교하는 데 사용되는 함수. (물론 지도 학습의 경우) MSE, categorical cross-entropy 등의 함수가 사용된다.
-
Optimizer: Neural Net에서 Linear function의 weight, bias 값을 어떻게 업데이트할지에 대해(어떻게 에러를 줄일 것인지) 사용되는 알고리즘. 기울기에 일정 상수(learning rate)를 곱해서 진행하는 gradient descent 등이 있다.
- Back propagation: feed forward의 반대 개념. y의 값, 즉 실제 데이터와 우리가 forward propagation을 해서 얻은 예상값과의 에러를 이전 층으로 다시 전파시키는 것을 반복하고, 이를 통해 Cost Function의 값을 계속해서 줄여나가고, 적합한 weight와 bias 값을 유추해내는 과정이다. Deep Neural Network에서는, 네트워크에 포함된 weight 값이 매우 많은데, 이들을 쉽게 다루기 위해 chain rule을 활용하는 것이 특징이다.
- Training: 모든 Input에 대해서 Feed Forwards와 Back Propagation을 수행하는 것이다.
강의를 듣고 But whatisa Neural Network? - YouTube 유튜브 영상을 함께 보았다. 이건 사실 CNN을 중심으로 한 설명이지만 뉴럴넷의 구조를 시각적으로 잘 보여주고 있고, Neuron이 하나의 Function이라는 것을 이해할 수 있게 해 주었다. Training을 통해 적절한 weight와 bias를 조절하는 과정도 애니메이션으로 잘 표현되어 있다.
Classification with Deep Learning
Regression vs. Classification
Regression은 수치 보간 (확률적 추정)
Classification은 ‘어떤 그룹’에 속했는지를 판별 (분류)
Classification의 경우에는 우리가 알고 있는 일반적인 함수의 형태처럼 X에 대한 Y의 값이 하나로 주어지는 것이 아니라, X의 값을 ‘분류’하는 것이다. 이때 X(Input), Y(Target)을 어떻게 표현할 수 있을까?
Binary Classification Output
- 입력이 어떤 Class{C1, C2}에 속할지에 대한 확률.
- 0-1까지의 값을 가진다.
Features
Neural Net의 Input에서 하나의 ‘특징’이 Feature가 된다. 즉, Input은 Feature의 N Size Array로 표현할 수 있다. 그러므로 여기서 Linear Function은 다항일차함수이다.
Feed Forward
Classification에서 Feed Forward는 기준선에 대한 거리를 확률 분포로 나타냄으로써 이 확률에 따라 속하는 Class를 도출할 수 있다. 거리를 0과 1 사이의 확률로 변환하기 위해 Sigmoid Function을 Activation Function으로 사용한다.
Error Function
Classification에서는 Error Function으로 MSE 대신 Cross-entropy 함수를 사용한다.
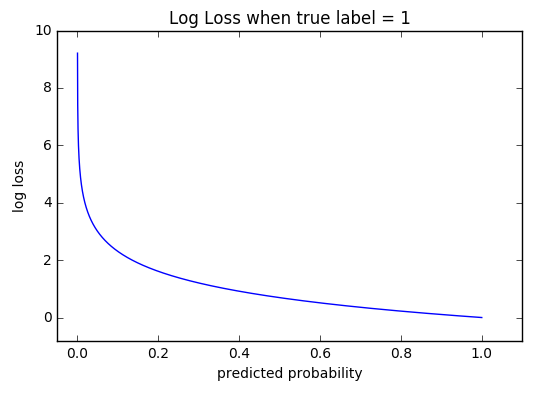 

Cross-entropy
확률 분포 간의 차이를 구하는 함수 (\(-\sum_{i} y_i log(y_i^\prime)\))
즉, 자연로그의 합에 부호를 바꾼 결과다. 자연로그의 그래프에서 x가 1에 가까워질수록 값이 0에 가까워지는 특성을 이용한 것이다. 전체 feature들의 확률을 종합하여 Error를 계산한다.
Class가 두 개일 경우에는 Binary Cross Entropy, 일반적인 경우에는 Categorical Cross Entropy를 사용한다.
Classification에서 Back Propagation은 이 Cross-entropy를 낮추는 것이 목표가 되고, Regression과 동일하게 gradient descent를 이용해서 에러의 최저점을 찾게 된다.
Multi Class Classification
- One-hot Encoding
- N개의 Class를 가진 데이터의 Y Target 값을 설정할 때에는, N개의 배열로 나타낸다.
- Softmax Function
- Activation Function으로 나온 값을 확률 분포로 변환하기 위해 사용된다. Classification Model을 만들 때에는 마지막에 꼭 Softmax Function이 들어가게 된다.
실습
UCI Machine Learning Repository: Adult Data Set를 이용해서 Keras와 Jupyter Notebook으로 실습을 진행했다. 인구 조사 데이터를 통해 소득 수준을 판별하는 간단한 regression, supervised learning 문제다.
x = np.linspace(1, 10, 1000) # 입력 생성
y = 2 * x + 1 # 출력 생성
# numpy를 사용하면 배열에 수식을 적용할 수 있다.
model = Sequential()
model.add(Dense(1, activation='linear', input_shape=(1,))) # Dense layer: hidden layer
model.summary() # for debugging
model.compile(loss='mse', optimizer='sgd')
model.fit(x, y, epochs=20) # training
pred_x = []
pred_x = np.append(pred_x, 12)
pred_x = np.append(pred_x, 14)
pred_y = model.predict(pred_x)
plt.plot(x, y)
plt.scatter(pred_x, pred_y)
plt.show()
print(model.get_weights())
모델을 compile할 때, accuracy metric을 추가하면 현재 학습하고 있는 데이터가 아닌 임의의 트레이닝 set에 포함된 input과 output을 이용해, 정확도를 함께 측정하게 된다. 이 경우 Overfitting 여부를 확인할 수 있다.
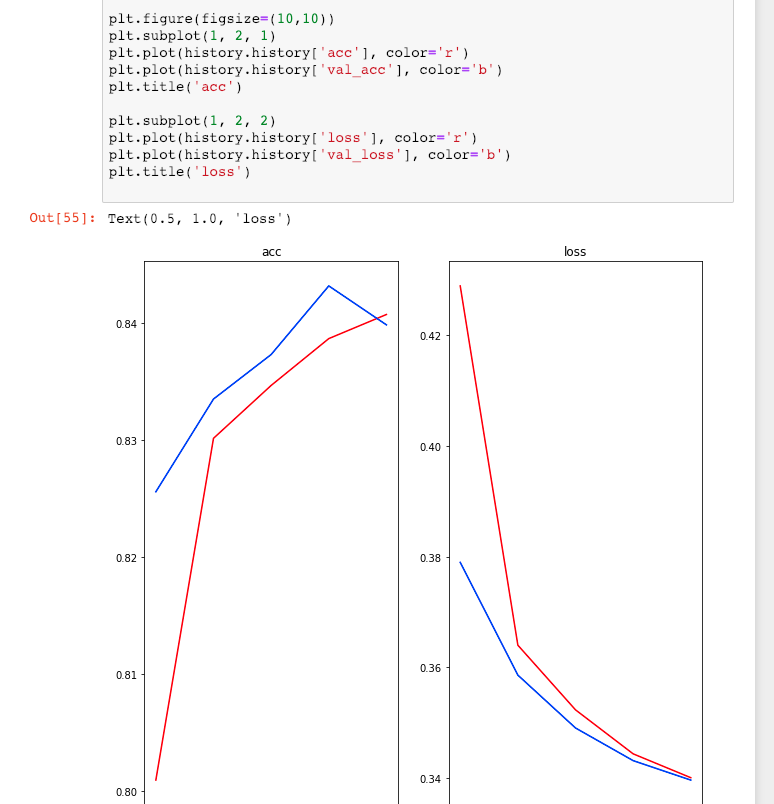
내 경우에도 실제로 이런 형태의 overfitting을 관찰할 수 있었다.
Overfitting: Accuracy는 증가하지만, Validation Accuracy는 감소하는 경우. 현재 ‘학습하고 있는’ 데이터들에 대한 정확도는 꾸준히 증가하지만, 그 외의 데이터들에 대해서는 정확도가 점점 떨어진다.
Overfitting을 방지하기 위해서 Dropout Layer를 추가할 수 있다.
model = Sequential()
model.add(Dense(32))
model.add(DropOut(0.5)) # 전달된 output의 일부를 사용하지 않는다
model.add(Dense(16))
..
- Keras Dense Layer에 대한 유용한 설명(레고 비유): 다층 퍼셉트론 레이어 이야기
Training에 사용되는 변수들 중 튜닝하거나 최적화해야하는 주 변수가 아니라, 자동으로 설정되는 변수들이 있다. 대표적으로,
- Learning Rate: Optimizer에 대한 변수, 일반적으로 default로 고정되어 있는데, learning rate를 높일수록 더 빠르게 학습이 진행된다. 그러나 너무 높을 경우 optimal point를 지나쳐 버릴 위험이 있다.
- Cost function: 일반적인 MSE를 사용할 수도 있고, cross-entropy를 사용할 수도 있다.
- Regularization Parameter: overfitting 문제를 피하기 위해 일반화 변수를 도입하고, weight decay의 속도를 조절하기 위한 용도로 사용한다.
- Training 반복 횟수
- Hidden Unit의 갯수
- 가중치 초기화
..등이 있는데, batch size도 그 중 하나이다.
Online Learning & Batch Learning
model.fit(X_train, Y_train, epochs=100, batch_size=100)
이렇게 학습할 때에 batch_size를 직접 지정해 줄 수 있다. batch_size가 전체 train set의 크기라면 Online Learning이고, 그보다 작게 직접 세팅해준다면 Batch Learning이다. 기본적으로 keras는 batch_size=32로 설정되어 있다. 둘의 차이는 다음과 같다.
- Online learning
- 한 epoch에서 단 한 번만 weight를 업데이트한다.
- 메모리를 많이 소모한다.
- Batch learning
- 한 epoch에서 batch size만큼 error가 누적되면 그 때 업데이트한다.
- 조금 느리지만 메모리를 덜 소모한다.
짧은 강좌 후기
이외에도 대표적인 MNIST와 같은 다른 테스트 데이터 셋으로 Classification과 Regression 각기 다른 타입으로 실습을 하면서 keras의 각 함수에 대응되는 이론적 배경들을 다시 짚어볼 수 있었다. 한 번 쭉 훑는다는 기분으로 빠르게 진행해서, 모든 내용을 다 정리해가며 공부하지는 못한 것이 조금 아쉽다. 하지만 이걸 바탕으로 앞으로 Coursera에 있는 (엄청 유명한!) Andrew Ng의 Machine Learning 강의도 차근차근 들어 볼 예정이다. 일단 강의의 남은 파트, CNN과 RNN에 대한 것들을 이어서 올려보겠다.