RNN(Recurrent Neural Network)
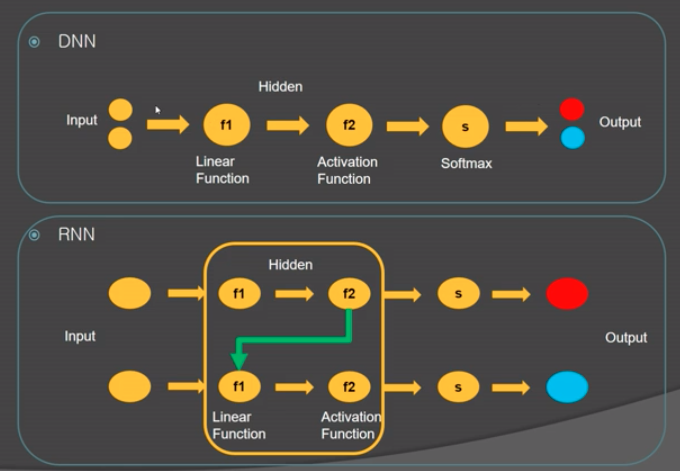
- 첫 번째 Input이 두 번째 Input에 영향을 주는 형태
- Input을 입력하는 순서가 결과에 영향을 준다.
- ex) 날씨 데이터, 교통량 등 축적된 데이터
RNN의 학습 유형
- Many to One
- Many to Many
- One to Many
- One to One
Gradient Vanishing
- Time Step을 200~300 이상으로 설정할 때 gradient vanishing 문제가 발생할 수 있다.
- Gradient가 1보다 작아졌는데 계속해서 곱하게 되면 0으로 수렴해서 ‘사라지게’ 된다. 이는 gradient 계산이 곱셈 연산으로 이루어져 있기 때문이다.
- 각 단계의 Gradient가 너무 작으면 반복이 발생할 때마다 weight가 충분히 변하지 않고, 더이상 학습이 되지 않을 것이다. (Global minimum을 찾을 수 없다)
- Sigmoid나 tangent 역함수의 경우에도 크거나 작은 x 값에 따라 기울기가 0에 가까워진다. Activation Function으로 Sigmoid 대신 ReLU를 사용하는 이유 중 하나도 Gradient Vanishing 때문이다.
LSTM, GRU Layer
LSTM (Long Term Shot Memory)
- Gradient vanishing 문제를 해결할 수 있도록 RNN cell을 변경한 구조.
- 곱셈으로 이루어진 gradient 연산에 덧셈을 추가하여 문제를 해결했다.
- 더 자세한 설명은 LSTM-RNN-Tutorial 이곳에서!
model = Sequential()
model.add(LSTM(256, input_shape=(10, 1)))
model.add(LSTM(256))
GRU (Gated Recurrent Unit)
model = Sequential()
model.add(GRU(256, input=shape(10, 1)))
model.add(GRU(256))
Input/Output
- Input은 (N Sample, N time step, Value)의 형태로 주어진다.
- Many to One: Output은 단순한 value 형태
- (N Sample, Value)
- ` return_sequences=False`
- Many to Many: Output은 Time Step을 고려한 3차원 데이터
- (N Sample, N time step, Value)
- ` return_sequences=True`
참고 링크 추가
- 헷갈리는 Batch/Epoch 개념: Epoch vs Batch Size vs Iterations – Towards Data Science